Less-experienced readers of brain MRI exams gain the greatest interpretation accuracy benefit from large language model (LLM) assistance, while the tool helps expert neuroradiologists only marginally, researchers have reported.
The findings point to where AI decision support delivers the most clinical value, wrote a team led by Severin Schramm, MD, of Technical University of Munich in Germany. The group's results were published May 26 in Radiology.
"[We found that] with increasing reader experience, LLM accuracy with reader-generated input improved, whereas accuracy gains from LLM assistance diminished," the authors noted.
Studies have demonstrated that LLMs can offer differential diagnoses based on textual radiologic findings, they wrote. But it's unclear how variations in reader-generated inputs affect LLM performance and clinical utility.
To this end, Schramm and colleagues conducted a study that evaluated how reader experience influences the diagnostic benefit of LLM assistance in brain MRI differential diagnosis. The research included 12 readers across three experience levels: four board-certified neuroradiologists, four radiology residents, and four neurology/neurosurgery residents without formal radiology training.
Each participant interpreted 40 brain MRI scans with confirmed diagnoses procured between January 2009 and April 2024, first submitting written imaging findings and their top-three differential diagnoses without AI assistance and then submitting revised diagnoses after reviewing suggestions generated by GPT-4.1 (OpenAI) from their own descriptions. For comparison, the team also used the same reader inputs with two additional models, Gemini 2.5 Pro (Google DeepMind) and DeepSeek-R1 (DeepSeek AI).
Overall, the researchers reported that LLM accuracy tracked closely with the quality of reader-provided inputs:
- For neuroradiologists, the three models achieved accuracy rates ranging from 78.8% to 83.8%.
- For radiology residents, accuracy ranged from 71.8% to 77.6%.
- For neurology/neurosurgery residents, accuracy varied from 63.2% to 67.1%.
But gains in top-three accuracy with LLM assistance diminished with increasing experience, Schramm and colleagues found.
- Neurology/neurosurgery residents improved their top-three accuracy by 19.4 percentage points (43.2% to 62.6%; p < 0.001).
- Radiology residents gained 14.7 points (59.6% to 74.4%; p < 0.001).
- Neuroradiologists improved by just 4.4 points (83.1% to 87.5%), a gain that did not reach statistical significance (p = 0.086).
Independent expert ratings of the imaging descriptions submitted to the models explained part of this pattern, the group wrote, noting that neuroradiologists produced the most correct and complete findings, while neurology/neurosurgery residents scored lowest on both dimensions. Experience was positively associated with both correctness (β = 0.11; p < 0.001) and completeness (β = 0.18; p = 0.002) of imaging findings.
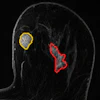
 Sample cases. (A) The correct diagnosis was progressive multifocal leukoencephalopathy. Although GPT-4.1 suggested the correct diagnosis based on imaging findings from both the neurosurgery resident and the neuroradiologist, only the neurosurgery resident benefited from it, though their diagnostic confidence remained low. (B) The correct diagnosis was subependymal giant cell astrocytoma. Although GPT-4.1 suggested the correct diagnosis based on the imaging findings provided by the neuroradiologist, neither of the two readers benefited from it. Imaging descriptions were translated from German to English for illustration purposes.Radiology
Sample cases. (A) The correct diagnosis was progressive multifocal leukoencephalopathy. Although GPT-4.1 suggested the correct diagnosis based on imaging findings from both the neurosurgery resident and the neuroradiologist, only the neurosurgery resident benefited from it, though their diagnostic confidence remained low. (B) The correct diagnosis was subependymal giant cell astrocytoma. Although GPT-4.1 suggested the correct diagnosis based on the imaging findings provided by the neuroradiologist, neither of the two readers benefited from it. Imaging descriptions were translated from German to English for illustration purposes.Radiology
"Although our case selection may not represent the diagnostic complexity of routine clinical practice, it targets scenarios where LLMs provide the greatest value and are likely to be consulted by radiologists for differential diagnosis," the group wrote. "In routine cases where radiologists quickly arrive at confident diagnoses, LLM-generated differential diagnoses offer limited benefit. The clinical utility of LLM assistance is most evident in challenging cases, where readers may struggle to formulate comprehensive differential diagnoses or lack confidence in their preliminary interpretations."
The study findings "paint an interesting picture for the future of human-AI collaboration in clinical practice," wrote Alan McMillan, PhD, of the University of Wisconsin School of Medicine and Public Health in Madison, in an accompanying editorial.
"Prospective multicenter clinical trials are urgently needed to evaluate the true impact of AI assistance on actual patient outcomes, workflow efficiency, and diagnostic turnaround times in real-world environments," McMillan concluded.
Access the full study here.