
 Dr. Filippo Pesapane, PhD, radiologist at the European Institute of Oncology (IEO) in Milan, led the study. His research focuses on the practical applications of AI in breast imaging and women's perceptions of AI in cancer diagnosis.Image courtesy of Dr. Pesapane
Dr. Filippo Pesapane, PhD, radiologist at the European Institute of Oncology (IEO) in Milan, led the study. His research focuses on the practical applications of AI in breast imaging and women's perceptions of AI in cancer diagnosis.Image courtesy of Dr. Pesapane
"The safety of AI in radiology depends not only on the algorithm, but also on the human–AI interaction around it," says Dr. Filippo Pesapane, PhD, a radiologist at the European Institute of Oncology (IEO) in Milan, who led the fully-crossed simulation reader study.
AI outputs are not cognitively neutral, the researchers found. A recommendation from an algorithm can act as a powerful signal, particularly when it appears with apparent confidence inside a clinical workflow. And when that signal is wrong, radiologists follow it more often than the field may be comfortable admitting.
Making cognitive bias measurable
Six breast radiologists, split equally into low-, medium-, and high-experience groups, independently reviewed 200 mammography examinations under three sequential conditions: unaided reading, AI-assisted reading, and AI-assisted reading with saliency-based explainable AI (XAI) heatmaps generated via Grad-CAM. Each reader completed all three phases, with at least one month between sessions to limit recall effects.
To make cognitive bias measurable under controlled conditions, the investigators deliberately perturbed 30% of the AI's BI-RADS-like recommendations by one category: enough to be plausible, not enough to be obviously wrong. Radiologists were not told. The remaining 70% retained the native AI output.
Two distinct bias types were assessed. Automation bias was measured when AI advice appeared before the radiologist's own decision, testing whether readers followed the algorithm without independent analysis. Anchoring-related revision bias was measured when AI was revealed after an initial read, testing whether readers inappropriately revised a correct first impression toward a wrong AI recommendation.
Explainable AI cut both rates
Under standard AI assistance, automation bias occurred in 36.1% of manipulated AI-first cases (65/180). Anchoring-related revision bias occurred in 33.9% of AI-second cases (61/180). When the AI was wrong, radiologists followed it roughly one-third of the time.
 Bias rates by experience level under standard AI versus explainable AI. All reductions were statistically significant (p < 0.01).Pesapane et al., European Radiology
Bias rates by experience level under standard AI versus explainable AI. All reductions were statistically significant (p < 0.01).Pesapane et al., European Radiology
Explainable AI cut both rates by roughly half. With saliency heatmaps alongside the AI recommendation, automation bias fell to 17.8% (32/180) and anchoring bias to 17.2% (31/180).
In adjusted mixed-effects models, XAI was associated with significantly lower odds of both bias types: aOR 0.56 (95% CI, 0.44–0.71) for automation bias and aOR 0.61 (95% CI, 0.48–0.78) for anchoring bias (both p < 0.001). On the non-manipulated subset, diagnostic accuracy improved from 86.2% unaided to 90.1% with AI plus XAI.
Experience matters, but doesn't fully protect
Junior radiologists were most susceptible. In the standard AI phase, low-experience readers showed automation bias rates of 41.7% and anchoring bias rates of 38.3%, compared to 30.0% and 28.3% in the most-experienced group. XAI produced the largest absolute reductions in junior readers, dropping automation bias from 41.7% to 20.0%.
But senior radiologists were not immune: even in the high-experience group, approximately one in six manipulated cases still resulted in a biased decision after XAI was introduced. Expertise, the study suggests, reduces vulnerability, it does not eliminate it.
Approximately one in five manipulated cases still led to a biased decision even when saliency heatmaps were available. The authors suggest several explanations: radiologists may misinterpret heatmap patterns, over-weight AI confidence despite ambiguous visual cues, or revert to heuristic reasoning under time pressure. Transparency, in other words, is necessary but not sufficient.
 Grad-CAM heatmaps showing the AI model's areas of attention overlaid on standard mammography views, as displayed to radiologists during the XAI-assisted reading sessions.Pesapane et al., European Radiology
Grad-CAM heatmaps showing the AI model's areas of attention overlaid on standard mammography views, as displayed to radiologists during the XAI-assisted reading sessions.Pesapane et al., European Radiology
The study draws a pointed comparison to the earlier failure of computer-aided detection (CAD) systems in mammography. While CAD's shortcomings are typically attributed to technical limitations, the authors argue that cognitive bias, overreliance on CAD marks, or second-guessing of correct initial reads may have been underrecognized contributors, and that the same vulnerability could recur with modern AI unless proactively addressed.
Call for safer AI workflow
A safer AI workflow may require an initial unaided read, explicit documentation of the reader's pre-AI impression, structured training on common AI failure modes, and discrepancy-based teaching focused on human-AI disagreement.
"The future of radiology AI will not be defined only by better models, It will also be defined by better interfaces, better workflows, and better cognitive discipline," Pesapane notes.
The larger benefit of XAI among less-experienced readers further suggests that this kind of training belongs in fellowship and early-career breast imaging education, not deferred until after deployment.
Revelance of cognitive safety
The study is framed around breast imaging, but the authors are explicit that automation bias and anchoring bias are not breast-specific phenomena. Any AI system that issues a categorical recommendation, risk score, heatmap, or prioritization signal may influence human interpretation in ways that sensitivity, specificity, AUC, and reading time do not capture.
The concept the authors advance, cognitive safety, may be as important to AI integration as algorithmic accuracy.
"A confident algorithm can improve diagnosis. But a confident algorithm can also make an error more persuasive", said Pesapane.
Limitations
The authors acknowledge several limitations. The study is single-center and used a dataset deliberately enriched for malignancy (50% malignant), with a 30% AI error rate far above what a deployed clinical system would produce.
The findings are best understood as a controlled demonstration of the direction and modifiability of cognitive vulnerability under discordant AI advice, not an estimate of real-world bias frequency in screening. With only six readers, subgroup findings by experience level should be interpreted cautiously.
The full article can be found here.
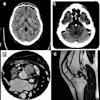
![A normal mammogram confirmed by three-year radiologic follow-up illustrates reader-marked regions of interest (ROIs) during (A) unaided (round 1) and (B) artificial intelligence (AI)–assisted (round 2) reading. Each colored dot represents an ROI for recall by a human reader. Readers could mark more than one ROI per case, represented by multiple dots of the same color. During AI-assisted reading, the AI system displayed three visible prompts: two with suspicion of malignancy scores of 35% (left mediolateral oblique [L MLO] and craniocaudal [L CC]) and one with a suspicion of malignancy score of 10% (right craniocaudal [R CC]), shown as polygonal overlays. Without AI, six of 10 readers (60%) marked a false-positive ROI. With AI assistance, this fell to two of 10 (20%). R MLO = right mediolateral oblique.](https://img.auntminnieeurope.com/mindful/smg/workspaces/default/uploads/2026/07/2026-07-14-radiology-mammogram-ai-auto-bias.H0bYO8QlWs.jpg?auto=format%2Ccompress&fit=crop&h=100&q=70&w=100)







![A normal mammogram confirmed by three-year radiologic follow-up illustrates reader-marked regions of interest (ROIs) during (A) unaided (round 1) and (B) artificial intelligence (AI)–assisted (round 2) reading. Each colored dot represents an ROI for recall by a human reader. Readers could mark more than one ROI per case, represented by multiple dots of the same color. During AI-assisted reading, the AI system displayed three visible prompts: two with suspicion of malignancy scores of 35% (left mediolateral oblique [L MLO] and craniocaudal [L CC]) and one with a suspicion of malignancy score of 10% (right craniocaudal [R CC]), shown as polygonal overlays. Without AI, six of 10 readers (60%) marked a false-positive ROI. With AI assistance, this fell to two of 10 (20%). R MLO = right mediolateral oblique.](https://img.auntminnieeurope.com/mindful/smg/workspaces/default/uploads/2026/07/2026-07-14-radiology-mammogram-ai-auto-bias.H0bYO8QlWs.jpg?auto=format%2Ccompress&dpr=2&fit=crop&h=167&q=70&w=250)









