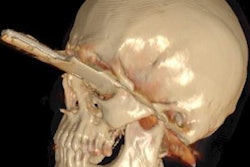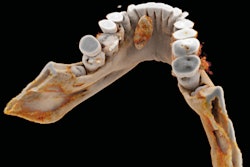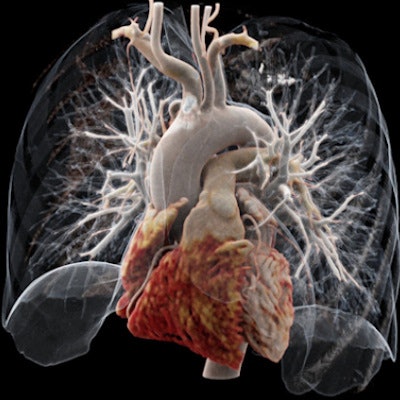
It's been touted as "3D on steroids," but many in radiology still aren't sure how cinematic rendering of medical images works. Fortunately, two new articles from the U.S. and Europe offer an explanation of the new technique, which creates stunningly lifelike images from scans.
In the papers, two separate research groups described their experiences to date with cinematic rendering. One group was from Johns Hopkins University and included 3D visualization expert Dr. Elliot Fishman, as well as Dr. Pamela Johnson, vice chair of education in the department of radiology at the university. The second group included Dr. Marwan Eid and Dr. Joseph Schoepf from the Medical University of South Carolina (MUSC), as well as collaborators from the University of Rome Sapienza in Italy and University Hospital Frankfurt in Germany.
Both groups see a promising future for cinematic rendering as an improvement over both 2D images and 3D volume rendering, currently the dominant mode for presenting 3D images.
"Cinematic rendering ... provides a lifelike representation of imaging data and may have potential for enhancing diagnostic utility compared with volume rendering, particularly in terms of a more natural and physically accurate image with improved shape and depth perception," Eid and colleagues wrote in their American Journal of Roentgenology paper (August 2017, Vol. 209:2, pp. 370-379).
Cinematic rendering at MUSC
Researchers at MUSC and Johns Hopkins are using cinematic rendering on an investigational basis. The technique is a feature in the work-in-progress syngo.via Frontier advanced visualization software package from Siemens Healthineers and has not yet received 510(k) clearance from the U.S. Food and Drug Administration (FDA), according to the company.
Eid began working with the technique about two years ago at MUSC and was "immediately amazed by it," he told AuntMinnieEurope.com. As Eid and Schoepf explained in their AJR paper, cinematic rendering represents a fundamental change in how reconstruction algorithms process data from modality scanners.
With volume rendering, CT datasets are processed in their entirety, resulting in an image that can be manipulated in real-time and that can show anatomic details from different perspectives. The reconstruction algorithm is based on principles of raycasting and local lighting models that stipulate that for each pixel in the image, one ray of light is cast through the volume and intersects a line of voxels. While volume-rendered images are better representations of target tissues than 2D slices, the model produces more artificial-looking images because it ignores the fact that light can be scattered or absorbed.
Cinematic rendering takes a different approach, Eid and Schoepf continued, drawing inspiration from the success of the animated movie industry, such as Pixar Animation Studios. The technique follows some of the early data reconstruction steps found in volume rendering, but rather than a single raycasting model, it instead assumes that the target is illuminated by billions of photons traveling from all possible directions. It's this model that gives cinematic-rendered images their photorealistic quality.

The MUSC team has found cinematic rendering to be most useful for complex studies, such as cases of congenital heart disease or follow-up of coronary artery bypass graft (CABG) procedures.
"If you look at graft or stent images, it's much more straightforward and easier for an observer to grasp," Schoepf told AuntMinnieEurope.com in an interview. "This gives you a particularly lifelike impression of what you are dealing with."
Eid acknowledged that there's a bit of a learning curve to working with cinematic-rendered images, but he said the technique is "pretty easy to use" once you are familiar with it. One way to look at it is as a less expensive version of a 3D printer, Eid and Schoepf believe.
Cinematic rendering at Johns Hopkins
Meanwhile, the group at Johns Hopkins has been working with cinematic rendering for about the past year, as Fishman explained in a recent talk at the International Society for Computed Tomography (ISCT) symposium.
Johnson, Fishman's co-author on the AJR paper (Vol. 209:2, pp. 309-312), sees cinematic rendering as part of radiology's move toward patient-centered imaging. The images are easier for patients to understand and can help radiologists create a bond with the patients.
"You can sit down with a patient and say, this is your tumor. You can show them their disease, help them understand better, and explain what you will do," Johnson told AuntMinnie.com. "Volume rendering has always been awesome, but you can see where it would be easier for a patient to understand what they are looking at when there is this much detail."
Johnson and the group at Johns Hopkins believe that cinematic rendering could potentially enable the detection of pathology not found on 2D or 3D volume-rendered images. For example, reconstructions of solid organs like the pancreas show the parenchyma of the target better and provide a better sense of its architecture and anatomic detail. It could also help predict which tumors will respond to chemotherapy.
"When we look at tumors, the texture we can see is amazing," Johnson said. "This is measuring things that we can't see."
The future
Johnson sees some drawbacks to cinematic rendering. The technique requires more computer horsepower and network bandwidth than volume rendering, especially if users want to create interactive images that can be manipulated in real-time. Also, too much realism can have its own drawbacks, such as when tissues that are obstructed from the "light source" appear darker.
Both MUSC and Johns Hopkins are planning research studies to demonstrate the utility of cinematic rendering for different clinical applications. Johnson even believes that the technique could lead to new clinical applications for existing imaging modalities, particularly CT.
"It will advance the utility of CT for musculoskeletal imaging," she said. "MRI is great for muscles and tendons, but when you have this level of detail, that's an area where you will see CT expand in diagnostic abilities."