Artificial intelligence (AI) can detect diseases from medical imaging with similar levels of accuracy as healthcare professionals, according to a new meta-analysis published on 24 September by Lancet Digital Health. However, the authors admit that only a tiny proportion of studies were of sufficient quality to be included in the analysis.
In their article, the international group of researchers sounded a strong note of caution about the true diagnostic value of deep learning. They believe the use of algorithms, big data, and computing power to emulate human learning and intelligence remains uncertain because of the lack of studies that directly compare the performance of humans and machines, or that validate AI's performance in real clinical environments.
"We reviewed over 20,500 articles, but less than 1% of these were sufficiently robust in their design and reporting that independent reviewers had high confidence in their claims," noted Prof. Alastair Denniston, PhD, a consultant ophthalmologist and honorary professor at the Institute of Inflammation and Ageing, University of Birmingham, in a Lancet press release.
Only 25 studies validated the AI models externally (using medical images from a different population), and just 14 studies actually compared the performance of AI and health professionals using the same test sample, added Denniston, who led the research.
"Within those handful of high-quality studies, we found that deep learning could indeed detect diseases ranging from cancers to eye diseases as accurately as health professionals. But it's important to note that AI did not substantially out-perform human diagnosis," he stated in the release.
Key goals and findings
The group conducted a systematic review and meta-analysis of all studies comparing the performance of deep learning models and health professionals in detecting diseases from medical imaging published between January 2012 and June 2019. They also evaluated study design, reporting, and clinical value.
From more than 20,000 unique abstracts, a mere 82 studies met their eligibility criteria for the review, and only 25 met their inclusion criteria for the meta-analysis. These 25 studies covered 13 different specialty areas, only two of which -- breast cancer and dermatological cancers -- were represented by more than three studies.
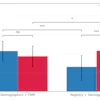
The study suggested equivalent performance of deep learning algorithms and healthcare professionals in the 14 studies that used the same out-of-sample validation dataset to compare their performances. The authors reported that deep-learning models had a slightly higher sensitivity and specificity in the studies than healthcare professionals (see table below).
| Deep learning vs. healthcare professionals for sensitivity and specificity | ||
| Healthcare professionals | Deep-learning models | |
| Pooled sensitivity | 86.4% | 87.0% |
| Pooled specificity | 90.5% | 92.5% |
Limitations and reflections
The authors noted several limitations in the methodology and reporting of AI diagnostic studies included in the analysis. Deep learning was often assessed in isolation in a way that does not reflect clinical practice. For example, only four studies provided health professionals with additional clinical information they would normally use to make a diagnosis in clinical practice.
Additionally, few prospective studies were done in real clinical environments, and the authors wrote that to determine diagnostic accuracy requires high-quality comparisons in patients, not just datasets. Poor reporting was also common, with most studies not reporting missing data, which limits the conclusions that can be drawn, they wrote.
"There is an inherent tension between the desire to use new, potentially life-saving diagnostics and the imperative to develop high-quality evidence in a way that can benefit patients and health systems in clinical practice," pointed out first author Dr. Xiaoxuan Liu, also from the University of Birmingham. "A key lesson from our work is that in AI -- as with any other part of healthcare -- good study design matters. Without it, you can easily introduce bias that skews your results."
These biases can lead to exaggerated claims of good performance for AI tools that do not translate into the real world, Liu continued. Good design and reporting of these studies is a key part of ensuring that the AI interventions that come through to patients are safe and effective.
"Evidence on how AI algorithms will change patient outcomes needs to come from comparisons with alternative diagnostic tests in randomized controlled trials," added co-author Dr. Livia Faes, from Moorfields Eye Hospital in London. "So far, there are hardly any such trials where diagnostic decisions made by an AI algorithm are acted upon to see what then happens to outcomes that really matter to patients, like timely treatment, time to discharge from hospital, or even survival rates."
Writing in a linked comment, Dr. Tessa Sundaram Cook, PhD, assistant professor of radiology at the University of Pennsylvania in Philadelphia, discussed whether AI can be effectively compared to the human physician working in the real world, where data are "messy, elusive, and imperfect."
"Perhaps the better conclusion is that, the narrow public body of work comparing AI to human physicians, AI is no worse than humans, but the data are sparse and it may be too soon to tell," she concluded.
The study was conducted by researchers from University Hospitals Birmingham National Health Service (NHS) Foundation Trust, Birmingham; University of Birmingham, Birmingham; Moorfields Eye Hospital NHS Foundation Trust, London; Cantonal Hospital of Lucerne, Lucerne, Switzerland; National Institute for Health Research Biomedical Research Centre for Ophthalmology, Moorfields Eye Hospital NHS Foundation Trust and UCL Institute of Ophthalmology, London; Ludwig Maximilian University of Munich, Munich, Germany; DeepMind, London; Scripps Research Translational Institute, La Jolla, California; and Medignition, Zurich.