
Top Story
Latest News

Esaote reports growth in fiscal year 2023
April 25, 2024

Sponsored
Register today for a FREE webinar 8 May at 6 p.m. CET
April 24, 2024

EUCAIM calls for new applicants and prepares for webinar
April 25, 2024

First patient dosed with ITM-31 in glioblastoma trial
April 23, 2024
Cases of the Week
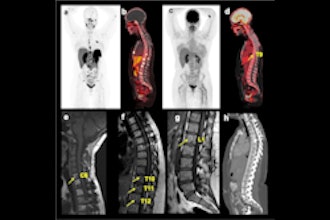
Check out our Cases of the Week!



More from AuntMinnieEurope
ESR releases movie to mark key moments of ECR 2024
April 23, 2024

Blackford, Annalise.ai enter partnership
April 23, 2024

Anger builds over 10% fee hike for RCR members
April 23, 2024






Accuray opens training facility in Switzerland
April 19, 2024

Raigmore Hospital in Scotland selects RayCare
April 17, 2024

Radiology pays tribute to Dutch pioneer Jacob Valk
April 18, 2024
